- Posts: 24
- Thank you received: 3
Welcome to the LimeSurvey Community Forum
Ask the community, share ideas, and connect with other LimeSurvey users!
Anzeige einer Auswahl an Texten anhand vorausgehender Ratings
- Malte
-
 Topic Author
Topic Author
- Offline
- Junior Member
-

Less
More
8 months 3 weeks ago #245562
by Malte
Anzeige einer Auswahl an Texten anhand vorausgehender Ratings was created by Malte
Bitte helfen Sie uns, Ihnen zu helfen und füllen Sie folgende Felder aus:
Ihre LimeSurvey-Version: Version 5.6.17+230426
Eigener Server oder LimeSurvey-Cloud: eigener Server
Genutzte Designvorlage: fruity
==================
Hallo,
ich habe einmal wieder eine Herausforderung beim Design einer Umfrage und wäre wie immer sehr dankbar für jeden Hinweis aus der Community:
In einer Umfrage sollen zunächst eine Reihe von Aussagen zu verschiedenen Themen/Bereichen auf einer Ratingantwortskala bewertet werden. Da zu jedem Bereich mehrere Aussagen präsentiert werden, wird anschließend per versteckter Gleichungsfrage zu jedem Thema/Bereich der Mittelwert der Ratings aller Aussagen zum entsprechenden Bereich/Thema gebildet.
Nun sollen zum Abschluss der Umfrage zu den Bereichen/Themen, die vorher die höchsten Ratings/Mittelwerte erhalten haben, weitere Informationen angezeigt werden. Folgende Herausforderungen habe ich nun:
Besten Dank & schönen Gruß,
Malte
Ihre LimeSurvey-Version: Version 5.6.17+230426
Eigener Server oder LimeSurvey-Cloud: eigener Server
Genutzte Designvorlage: fruity
==================
Hallo,
ich habe einmal wieder eine Herausforderung beim Design einer Umfrage und wäre wie immer sehr dankbar für jeden Hinweis aus der Community:
In einer Umfrage sollen zunächst eine Reihe von Aussagen zu verschiedenen Themen/Bereichen auf einer Ratingantwortskala bewertet werden. Da zu jedem Bereich mehrere Aussagen präsentiert werden, wird anschließend per versteckter Gleichungsfrage zu jedem Thema/Bereich der Mittelwert der Ratings aller Aussagen zum entsprechenden Bereich/Thema gebildet.
Nun sollen zum Abschluss der Umfrage zu den Bereichen/Themen, die vorher die höchsten Ratings/Mittelwerte erhalten haben, weitere Informationen angezeigt werden. Folgende Herausforderungen habe ich nun:
- Es sollen nur die 3 Bereiche/Themen mit den höchsten Ratings/Mittelwerten angezeigt werden, insgesamt werden aber Aussagen zu deutlich mehr Bereiche/Themen bewertet.
- Als Ausnahme sollen bei identisch hohen Mittelwerten unter den drei am höchsten bewerteten Bereichen/Themen, alle dieser Bereiche/Themen angezeigt werden. Also z.B.: 1,1,2,3 oder extremer 1,2,2,2,3,3,3,3
- Die Reihenfolge der Präsentation der weiteren Informationen soll der Rangreihenfolge der Bewertungen entsprechen, d.h. Informationen zum am höchsten bewerteten Bereich/Thema zuerst etc. - bei gleichem Platz in der Rangreihenfolge wäre natürlich eine zufällige Anordnung der Bereiche/Themen mit einer identischen Bewertung spitze
Besten Dank & schönen Gruß,
Malte
Please Log in to join the conversation.

- Joffm
-

- Away
- LimeSurvey Community Team
-

Less
More
- Posts: 12941
- Thank you received: 3979
8 months 3 weeks ago #245565
by Joffm
Volunteers are not paid.
Not because they are worthless, but because they are priceless
Replied by Joffm on topic Anzeige einer Auswahl an Texten anhand vorausgehender Ratings
Hallo, Malte,
recht kurz vorweg:
Was willst Du genau auswählen bei identischen Mittelwerten?
Du sagst "die drei am höchsten bewerteten Bereiche"
Willst Du nun die drei höchstbewerteten Gruppen auswählen?
Im ersten Beispiel 1,1,2,3 ist ja klar, dass 1 und 1 beide auf dem ersten Platz liegen, 2 auf dem dritten (rein sportlich betrachtet)
Und im zweiten 1,2,2,2,3,3,... haben wir eben die 1 auf dem ersten Platz und alle 2 auf dem zweiten, die 3 landet dann auf dem fünften Platz..
Also soll - nach meinem Verständnis - alles angezeigt werden, was auf einem "Medaillenplatz" landet; die Holzmedaille ist außen vor.
Oder ist Deine Idee, nur die absoluten Werte der Mittelwerte zu betrachten, davon die drei höchsten zu nehmen, unabhängig wie oft sie auftreten?
Ideen dazu findest Du in meinem "Tutorial 4: Gleichungen, Zufall..". Sollte im Moment auf Seite 10 hier im deutschen Teil sein.
Dort wird gezeigt, wie Du

Dies als Lesestoff für die Zeit, in der ich mich - nachdem Du den lss Export der Umfrage geschickt hast - auch näher damit beschäftige.
Um eine Lösung mit einigen Funktionen zu finden, solltest Du Dir z.B. vorstellen, vor Dir auf dem Schreibtisch 10 Zettelchen mit irgendwelchen Mittelwerten zu haben.
Wie würdest Du jetzt - Schritt für Schritt - vorgehen, um die letztendlich gewünschten Zettelchen/Gruppen herauszubekommen?
Ich fange einmal an:
1. Bestimme den Höchstwert aller Mittelwerte
2. Suche den/die Zettelchen mit diesem Wert
3. Nimm diese(s) Zettelchen und lege es/sie zur Seite.
...
Danach versuchst Du dies in eine Folge von Gleichungsfragen zu übersetzen
Denke daran, Du kannst alle implementierten Funktionen benutzen.
[url] manual.limesurvey.org/ExpressionScript_-...mplemented_functions [/url]
Für das Erste gibt es die Funktion "max(n1,n2,n3,...)"
Also, her mit dem lss Export eines Prototypen.
Und denke an die genaue Definition, welches die später anzuzeigenden Gruppen sind.
Bei Mittelwerten wie
G1: 1.23
G2: 2.41
G3: 3.12
G4: 1.23
G5: 4.75
G6: 3.12
sollen es die Gruppen G1, G4, G2 sein oder G1, G4, G2, G3, G5
Joffm
recht kurz vorweg:
Was willst Du genau auswählen bei identischen Mittelwerten?
Du sagst "die drei am höchsten bewerteten Bereiche"
Willst Du nun die drei höchstbewerteten Gruppen auswählen?
Im ersten Beispiel 1,1,2,3 ist ja klar, dass 1 und 1 beide auf dem ersten Platz liegen, 2 auf dem dritten (rein sportlich betrachtet)
Und im zweiten 1,2,2,2,3,3,... haben wir eben die 1 auf dem ersten Platz und alle 2 auf dem zweiten, die 3 landet dann auf dem fünften Platz..
Also soll - nach meinem Verständnis - alles angezeigt werden, was auf einem "Medaillenplatz" landet; die Holzmedaille ist außen vor.
Oder ist Deine Idee, nur die absoluten Werte der Mittelwerte zu betrachten, davon die drei höchsten zu nehmen, unabhängig wie oft sie auftreten?
Ideen dazu findest Du in meinem "Tutorial 4: Gleichungen, Zufall..". Sollte im Moment auf Seite 10 hier im deutschen Teil sein.
Dort wird gezeigt, wie Du
nicht mit simplen Operatoren, aber mit simplen Funktionen, und natürlich nicht "unübersichtlich", arbeiten kannst.Bevor ich weiter versuche, das Ganze über eine unübersichtliche Reihe von Konditionen mit simplen Operatoren ("<" / ">" /"<="/">=") zu lösen
Dies als Lesestoff für die Zeit, in der ich mich - nachdem Du den lss Export der Umfrage geschickt hast - auch näher damit beschäftige.
Um eine Lösung mit einigen Funktionen zu finden, solltest Du Dir z.B. vorstellen, vor Dir auf dem Schreibtisch 10 Zettelchen mit irgendwelchen Mittelwerten zu haben.
Wie würdest Du jetzt - Schritt für Schritt - vorgehen, um die letztendlich gewünschten Zettelchen/Gruppen herauszubekommen?
Ich fange einmal an:
1. Bestimme den Höchstwert aller Mittelwerte
2. Suche den/die Zettelchen mit diesem Wert
3. Nimm diese(s) Zettelchen und lege es/sie zur Seite.
...
Danach versuchst Du dies in eine Folge von Gleichungsfragen zu übersetzen
Denke daran, Du kannst alle implementierten Funktionen benutzen.
[url] manual.limesurvey.org/ExpressionScript_-...mplemented_functions [/url]
Für das Erste gibt es die Funktion "max(n1,n2,n3,...)"
Also, her mit dem lss Export eines Prototypen.
Und denke an die genaue Definition, welches die später anzuzeigenden Gruppen sind.
Bei Mittelwerten wie
G1: 1.23
G2: 2.41
G3: 3.12
G4: 1.23
G5: 4.75
G6: 3.12
sollen es die Gruppen G1, G4, G2 sein oder G1, G4, G2, G3, G5
Joffm
Volunteers are not paid.
Not because they are worthless, but because they are priceless
Please Log in to join the conversation.
- Malte
-
Topic Author
- Offline
- Junior Member
-
Less
More
- Posts: 24
- Thank you received: 3
8 months 3 weeks ago #245573
by Malte
Replied by Malte on topic Anzeige einer Auswahl an Texten anhand vorausgehender Ratings
Hallo Joffm,
besten Dank für Deine rasche Antwort!
Ich hatte mich hinsichtlich der anzuzeigenden Informationen bei mehrfach besetzten Rangplätzen leider nicht präzise ausgedrückt. Was ich meinte, entspricht Deiner ersten Vermutung, d.h. bei "1,1,2,3" sollen angezeigt werden "1" & "1" & "2" bzw. bei "1,2,2,2,3,3,3,3" - "1" & "2" & "2" & "2" bzw. für Dein Beispiel:
Bei Mittelwerten wie
G1: 1.23
G2: 2.41
G3: 3.12
G4: 1.23
G5: 4.75
G6: 3.12
sollen es die Gruppen G1, G4, G2 seinoder G1, G4, G2, G3, G6
Bei den Expression-Script-Funktionen hatte ich die zum Maximun auch schon entdeckt, war mit aber hinsichtlich der weiteren Rangplätze etwas unsicher. Danke aber auch für den Hinweis zum Zettel-Sortieren-Vorgehen - ich schaue zudem noch in Dein Tutorial, bastel weiter an einer Test-Umfrage und lade die Struktur dann hier hoch.
Schönen Gruß,
Malte
besten Dank für Deine rasche Antwort!
Ich hatte mich hinsichtlich der anzuzeigenden Informationen bei mehrfach besetzten Rangplätzen leider nicht präzise ausgedrückt. Was ich meinte, entspricht Deiner ersten Vermutung, d.h. bei "1,1,2,3" sollen angezeigt werden "1" & "1" & "2" bzw. bei "1,2,2,2,3,3,3,3" - "1" & "2" & "2" & "2" bzw. für Dein Beispiel:
Bei Mittelwerten wie
G1: 1.23
G2: 2.41
G3: 3.12
G4: 1.23
G5: 4.75
G6: 3.12
sollen es die Gruppen G1, G4, G2 sein
Bei den Expression-Script-Funktionen hatte ich die zum Maximun auch schon entdeckt, war mit aber hinsichtlich der weiteren Rangplätze etwas unsicher. Danke aber auch für den Hinweis zum Zettel-Sortieren-Vorgehen - ich schaue zudem noch in Dein Tutorial, bastel weiter an einer Test-Umfrage und lade die Struktur dann hier hoch.
Schönen Gruß,
Malte
Please Log in to join the conversation.
- Malte
-
Topic Author
- Offline
- Junior Member
-
Less
More
- Posts: 24
- Thank you received: 3
8 months 2 weeks ago #245708
by Malte
Replied by Malte on topic Anzeige einer Auswahl an Texten anhand vorausgehender Ratings
Hallo,
ich habe nun eine Lösung für die Darstellung der Informationen zu allen Themen/Bereichen, deren Bewertung auf den obersten Rangplätzen landet, gefunden - siehe hochgeladene Test-Umfrage. Hier habe ich erst mal nur die ersten beiden Rangplätze berücksichtigt, aber das Ganze ist ja beliebig erweiterbar.
Das Anzeigen der Informationen habe ich für jeden Rangplatz über eine Frage vom Typ "Mehrfachauswahl" umgesetzt, da hier leicht die Reihenfolge aller Themen/Bereiche, die zusammen auf diesem Rangplatz landen, randomisiert werden kann.
Jetzt bräuchte ich nur noch einen Hinweis, wie ich die Auswahl-Kästchen vor den Antwortoptionen bei der Mehrfachauswahl-Frage verstecken kann.
Schönen Gruß,
Malte
ich habe nun eine Lösung für die Darstellung der Informationen zu allen Themen/Bereichen, deren Bewertung auf den obersten Rangplätzen landet, gefunden - siehe hochgeladene Test-Umfrage. Hier habe ich erst mal nur die ersten beiden Rangplätze berücksichtigt, aber das Ganze ist ja beliebig erweiterbar.
Das Anzeigen der Informationen habe ich für jeden Rangplatz über eine Frage vom Typ "Mehrfachauswahl" umgesetzt, da hier leicht die Reihenfolge aller Themen/Bereiche, die zusammen auf diesem Rangplatz landen, randomisiert werden kann.
Jetzt bräuchte ich nur noch einen Hinweis, wie ich die Auswahl-Kästchen vor den Antwortoptionen bei der Mehrfachauswahl-Frage verstecken kann.
Schönen Gruß,
Malte
Attachments:
Please Log in to join the conversation.
- Joffm
-
- Away
- LimeSurvey Community Team
-
Less
More
- Posts: 12941
- Thank you received: 3979
8 months 2 weeks ago #245718
by Joffm
Volunteers are not paid.
Not because they are worthless, but because they are priceless
Replied by Joffm on topic Anzeige einer Auswahl an Texten anhand vorausgehender Ratings
Hallo, Malte,
eine ähnliche Lösung hatte ich auch bereits vorbereitet.
Ich benutze einen am Anfang erstellten "Container" (einfach "mehrfache kurze Texte"),
Dieser hat den Vorteil, dass man die Werte dort zuweist, und alle diese Gleichungen in eine einzige Frage schreiben kann.
1. Speichere alle Mittelwerte hinein (Base1)
2. Bestimme das Maximum aller dieser Zellen (Max1)
3. Erzeuge einen String, der Platzhalter für die übereinstimmenden Werte enthält (A=Mittelwert1, B=Mittelwert2,...) (G1)
Ist die Länge des Strings kleiner als 3:
4. Setze die "abgearbeiteten" Werte auf 0 (Base2)
5. Bestimme das Maximum aller dieser Zellen (Max2)
6. Erzeuge einen String, der Platzhalter für die übereinstimmenden Werte enthält (A=Mittelwert1, B=Mittelwert2,...) (G2)
Ist die Länge beider Strings immer noch kleiner als 3:
7. Setze die "abgearbeiteten" Werte auf 0 (Base3)
8. Bestimme das Maximum aller dieser Zellen (Max3)
9. Erzeuge einen String, der Platzhalter für die übereinstimmenden Werte enthält (A=Mittelwert1, B=Mittelwert2,...) (G3)
Jetzt kannst Du diese Strings benutzen, um Deine Anzeigen zu machen.
Kommt es nur darauf an, ob die Matrix dazugehörte, würde ich sie "joinen" (was ich am Schluss getan habe)
Ich erhalte etwas wie "#CFBD"
Die Raute am Anfang dient dazu, dass, im Falle der Benutzung von "strpos" keine Kollision bezüglich des Rückfgabewertes entsteht.
Denn
strpos("CFBD","A") ergibt 0, was hier bedeutet "nicht vorhanden"
strpos("CFBD","C") ergibt 0, was hier bedeutet "an der Stelle 0" (strpos beginnt die Zählung bei 0.
Aber mit der Raute
strpos("#CFBD","C") ergibt 1
Oder, wenn es Dir mehr im die Reihenfolge geht, und Du mit "substr" arbeitest, kannst Du die Raute natürlich weglassen
substr("CFBD",0,1) ergibt dann "C", Zählung beginnt auch bei 0.
Falls Du aber explizit auf den höchsten, den zweithöchsten Mittelwert eingehen willst, benutzt Du sie getrennt "Der String G1 enthält die Matrizen mit dem höchsten Mittelwert, der String G2, die mit dem zweithöchsten Mittelwert,..."
Vielleicht so (ich weiß es ja nicht)

Und jetzt endlich die lss
Joffm
P.S.
Ich habe Deine Lösung noch nicht vollständig durchgeschaut, werde aber auf jeden Fall noch ein Feedback geben.
eine ähnliche Lösung hatte ich auch bereits vorbereitet.
Ich benutze einen am Anfang erstellten "Container" (einfach "mehrfache kurze Texte"),
Dieser hat den Vorteil, dass man die Werte dort zuweist, und alle diese Gleichungen in eine einzige Frage schreiben kann.
1. Speichere alle Mittelwerte hinein (Base1)
2. Bestimme das Maximum aller dieser Zellen (Max1)
3. Erzeuge einen String, der Platzhalter für die übereinstimmenden Werte enthält (A=Mittelwert1, B=Mittelwert2,...) (G1)
Ist die Länge des Strings kleiner als 3:
4. Setze die "abgearbeiteten" Werte auf 0 (Base2)
5. Bestimme das Maximum aller dieser Zellen (Max2)
6. Erzeuge einen String, der Platzhalter für die übereinstimmenden Werte enthält (A=Mittelwert1, B=Mittelwert2,...) (G2)
Ist die Länge beider Strings immer noch kleiner als 3:
7. Setze die "abgearbeiteten" Werte auf 0 (Base3)
8. Bestimme das Maximum aller dieser Zellen (Max3)
9. Erzeuge einen String, der Platzhalter für die übereinstimmenden Werte enthält (A=Mittelwert1, B=Mittelwert2,...) (G3)
Jetzt kannst Du diese Strings benutzen, um Deine Anzeigen zu machen.
Kommt es nur darauf an, ob die Matrix dazugehörte, würde ich sie "joinen" (was ich am Schluss getan habe)
Ich erhalte etwas wie "#CFBD"
Die Raute am Anfang dient dazu, dass, im Falle der Benutzung von "strpos" keine Kollision bezüglich des Rückfgabewertes entsteht.
Denn
strpos("CFBD","A") ergibt 0, was hier bedeutet "nicht vorhanden"
strpos("CFBD","C") ergibt 0, was hier bedeutet "an der Stelle 0" (strpos beginnt die Zählung bei 0.
Aber mit der Raute
strpos("#CFBD","C") ergibt 1
Oder, wenn es Dir mehr im die Reihenfolge geht, und Du mit "substr" arbeitest, kannst Du die Raute natürlich weglassen
substr("CFBD",0,1) ergibt dann "C", Zählung beginnt auch bei 0.
Falls Du aber explizit auf den höchsten, den zweithöchsten Mittelwert eingehen willst, benutzt Du sie getrennt "Der String G1 enthält die Matrizen mit dem höchsten Mittelwert, der String G2, die mit dem zweithöchsten Mittelwert,..."
Vielleicht so (ich weiß es ja nicht)
Und jetzt endlich die lss
Joffm
P.S.
Ich habe Deine Lösung noch nicht vollständig durchgeschaut, werde aber auf jeden Fall noch ein Feedback geben.
Volunteers are not paid.
Not because they are worthless, but because they are priceless
Please Log in to join the conversation.
- Joffm
-
- Away
- LimeSurvey Community Team
-
Less
More
- Posts: 12941
- Thank you received: 3979
8 months 2 weeks ago #245720
by Joffm
Volunteers are not paid.
Not because they are worthless, but because they are priceless
Replied by Joffm on topic Anzeige einer Auswahl an Texten anhand vorausgehender Ratings
Und dann hänge ich nicht einmal die finale lss an. (Vergreisung?)
Volunteers are not paid.
Not because they are worthless, but because they are priceless
The following user(s) said Thank You: Malte
Please Log in to join the conversation.
- Malte
-
Topic Author
- Offline
- Junior Member
-
Less
More
- Posts: 24
- Thank you received: 3
8 months 2 weeks ago #245721
by Malte
Replied by Malte on topic Anzeige einer Auswahl an Texten anhand vorausgehender Ratings
Hallo Joffm,
besten Dank für die vielen hilfreichen Hinweise!
V.a. das Organisieren aller Gleichungen für die Bildung der Mittelwerte in einem Container macht die Sache deutlich übersichtlicher.
Mit der Umwandlung der aufgrund des Mittelwerts in einer bestimmten Höhe ausgewählten Bereiche/Themen in einen String muss ich mich nochmal genauer auseinandersetzen (hier kann man ja bestimmt auch die Reihenfolge, in der die Informationen innerhalb einer einzigen Textanzeige-Frage dargestellt werden, randomisieren, aber ich könnte mir auch vorstellen, dass durch die Verwendung mehrere Fragen die Rangplätze optisch stärker hervorgehoben werden).
Ich hatte aber tatsächlich bislang versäumt, ein Limit dafür einzubauen, dass keine weiteren Rangplätze berücksichtigt werden, wenn die grundlegend angestrebte Zahl an Bereichen/Themen, zu denen weitere Information dargestellt werden, bereits auf mit dem vorausgehenden Rangplatz erreicht sind. Das habe ich mal eben ergänzt - siehe aktualisierte .lss.
Schönen Gruß,
Malte
besten Dank für die vielen hilfreichen Hinweise!
V.a. das Organisieren aller Gleichungen für die Bildung der Mittelwerte in einem Container macht die Sache deutlich übersichtlicher.
Mit der Umwandlung der aufgrund des Mittelwerts in einer bestimmten Höhe ausgewählten Bereiche/Themen in einen String muss ich mich nochmal genauer auseinandersetzen (hier kann man ja bestimmt auch die Reihenfolge, in der die Informationen innerhalb einer einzigen Textanzeige-Frage dargestellt werden, randomisieren, aber ich könnte mir auch vorstellen, dass durch die Verwendung mehrere Fragen die Rangplätze optisch stärker hervorgehoben werden).
Ich hatte aber tatsächlich bislang versäumt, ein Limit dafür einzubauen, dass keine weiteren Rangplätze berücksichtigt werden, wenn die grundlegend angestrebte Zahl an Bereichen/Themen, zu denen weitere Information dargestellt werden, bereits auf mit dem vorausgehenden Rangplatz erreicht sind. Das habe ich mal eben ergänzt - siehe aktualisierte .lss.
Schönen Gruß,
Malte
Attachments:
Please Log in to join the conversation.
- Joffm
-
- Away
- LimeSurvey Community Team
-
Less
More
- Posts: 12941
- Thank you received: 3979
8 months 2 weeks ago - 8 months 2 weeks ago #245724
by Joffm
Ist aber auch nicht notwendig; dazu gibt es ja die Randomisierungsgruppe.
Ich habe mir einmal dies vorgestellt.
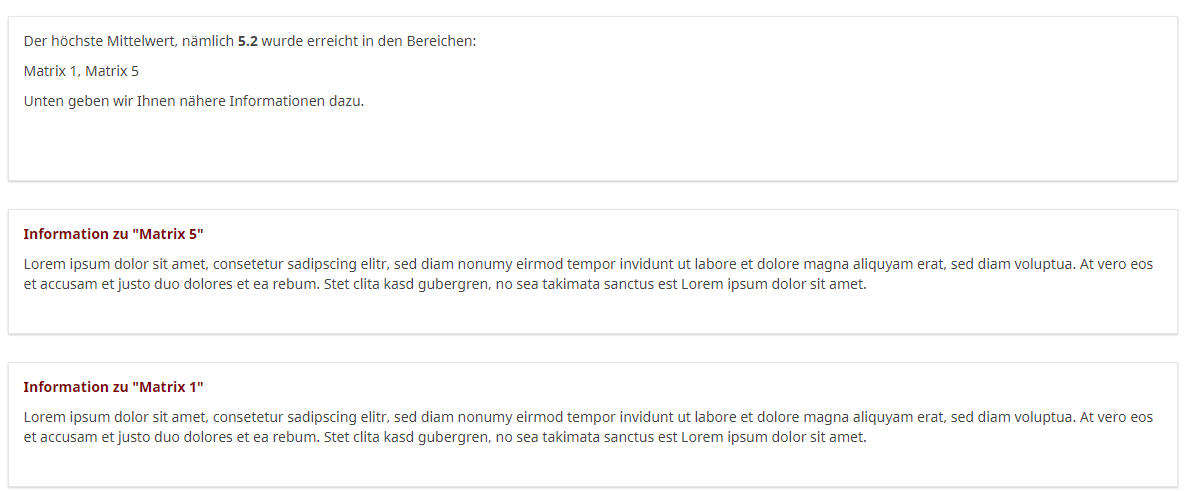

Hier habe ich für jeden Bereich eine Textanzeige-Frage mit der Bedingung, dass der entsprechende Buchstabe im String vorhanden ist und demselben Randomisierungsgruppennamen für alle.
Und oben drüber eben so eine allgemeine Info. Hier dann Singilar/Plural über "tayloring".
Das ist alles ohne viel "Schönheit.
Sinnvoll wäre auch, diese einzelnen Textanzeige-Fragen mit den css-Klassen "no-bottom" und "no-question" optisch zu verschmelzen
Joffm
Volunteers are not paid.
Not because they are worthless, but because they are priceless
Replied by Joffm on topic Anzeige einer Auswahl an Texten anhand vorausgehender Ratings
Nee, kann man nicht, wenn man nicht verstärkt in javascript einsteigen will.(hier kann man ja bestimmt auch die Reihenfolge, in der die Informationen innerhalb einer einzigen Textanzeige-Frage dargestellt werden, randomisieren,
Ist aber auch nicht notwendig; dazu gibt es ja die Randomisierungsgruppe.
Ich habe mir einmal dies vorgestellt.
Hier habe ich für jeden Bereich eine Textanzeige-Frage mit der Bedingung, dass der entsprechende Buchstabe im String vorhanden ist und demselben Randomisierungsgruppennamen für alle.
Und oben drüber eben so eine allgemeine Info. Hier dann Singilar/Plural über "tayloring".
Das ist alles ohne viel "Schönheit.
Sinnvoll wäre auch, diese einzelnen Textanzeige-Fragen mit den css-Klassen "no-bottom" und "no-question" optisch zu verschmelzen
Joffm
Volunteers are not paid.
Not because they are worthless, but because they are priceless
Last edit: 8 months 2 weeks ago by Joffm.
Please Log in to join the conversation.
Moderators: Joffm