- Posts: 12906
- Thank you received: 3969
Welcome to the LimeSurvey Community Forum
Ask the community, share ideas, and connect with other LimeSurvey users!
Probleme bei der Randomisierung "undefinierte Variable"
- Stadalsti_112211
-
 Topic Author
Topic Author
- Visitor
-

6 years 10 months ago #155249
by Stadalsti_112211
Probleme bei der Randomisierung "undefinierte Variable" was created by Stadalsti_112211
Hallo
ich versuche momentan folgendes Problem zu lösen und beiße mir daran die Zähne aus.
Ich benötige ein Studiendesign, bei dem die Probanden zufällig in 4 Gruppen zugeordnet werden und dementsprechend unterschiedliche Fragegruppen präsentiert bekommen.
Hierfür habe ich zu Beginn der Studie in einer Seperaten FragenGruppe eine Frage mit folgenden Befehl erstellt "{rand(1,4)}".
In den darauf folgenden Fragegruppen habe ich entsprechend der benötigten Reihenfolge die Relevanzgleichungen ((random==1)) etc. eingefügt. Leider funktioniert das bei mir nicht entsprechend der Anleitungen diverser Seiten.
Es kommt die Fehlermeldung, dass "random" eine undefinierte Variable ist in der Zeile ((random==1)).
In meiner Verzweiflung habe ich auch andere Schreibweisen wie ((random== "1")) etc getestet, was das Problem aber nicht behoben hat.
Hat jemand eine Idee woran das liegen könnte?
Achja, w
 enn ich statt "{rand(1,4)}" den Befehl {if(randnumber >= 0, randnumber, rand(1,4))} nutze, wird mir auch hier zurückgemeldet, dass randnumber eine undefinierte Variable ist.
enn ich statt "{rand(1,4)}" den Befehl {if(randnumber >= 0, randnumber, rand(1,4))} nutze, wird mir auch hier zurückgemeldet, dass randnumber eine undefinierte Variable ist.
ich versuche momentan folgendes Problem zu lösen und beiße mir daran die Zähne aus.
Ich benötige ein Studiendesign, bei dem die Probanden zufällig in 4 Gruppen zugeordnet werden und dementsprechend unterschiedliche Fragegruppen präsentiert bekommen.
Hierfür habe ich zu Beginn der Studie in einer Seperaten FragenGruppe eine Frage mit folgenden Befehl erstellt "{rand(1,4)}".
In den darauf folgenden Fragegruppen habe ich entsprechend der benötigten Reihenfolge die Relevanzgleichungen ((random==1)) etc. eingefügt. Leider funktioniert das bei mir nicht entsprechend der Anleitungen diverser Seiten.
Es kommt die Fehlermeldung, dass "random" eine undefinierte Variable ist in der Zeile ((random==1)).
In meiner Verzweiflung habe ich auch andere Schreibweisen wie ((random== "1")) etc getestet, was das Problem aber nicht behoben hat.
Hat jemand eine Idee woran das liegen könnte?
Achja, w
The topic has been locked.

- Stadalsti_112211
-
Topic Author
- Visitor
-
6 years 10 months ago #155273
by Stadalsti_112211
Replied by Stadalsti_112211 on topic Probleme bei der Randomisierung "undefinierte Variable"
Problem hat sich gelöst.
The topic has been locked.
- Joffm
-

- Offline
- LimeSurvey Community Team
-

Less
More
6 years 10 months ago #155320
by Joffm
Volunteers are not paid.
Not because they are worthless, but because they are priceless
Replied by Joffm on topic Probleme bei der Randomisierung "undefinierte Variable"
Hallo Stadalsti,
ich habe es ledier erst heute gesehen.
Aber sag nicht "Das Problem hat sich gelöst".
Sag lieber, dass Du Deinen Fehler gefunden hast.
Nur so nebenbei
Joffm
ich habe es ledier erst heute gesehen.
Aber sag nicht "Das Problem hat sich gelöst".
Sag lieber, dass Du Deinen Fehler gefunden hast.
Nur so nebenbei
Joffm
Volunteers are not paid.
Not because they are worthless, but because they are priceless
The topic has been locked.
- Asillnis_200501
-
- Offline
- Banned
-

Less
More
- Posts: 5
- Thank you received: 0
4 years 8 months ago #187724
by Asillnis_200501
Replied by Asillnis_200501 on topic Probleme bei der Randomisierung "undefinierte Variable"
Hallo Stadalsti und Joffm,
ich stehe vor demselben "Fehler". Schade, dass du nicht die Lösung beschrieben hast.
ich stehe vor demselben "Fehler". Schade, dass du nicht die Lösung beschrieben hast.
The topic has been locked.
- holch
-

- Offline
- LimeSurvey Community Team
-
Less
More
- Posts: 11639
- Thank you received: 2738
4 years 8 months ago #187727
by holch
I answer at the LimeSurvey forum in my spare time, I'm not a LimeSurvey GmbH employee.
No support via private message.
Replied by holch on topic Probleme bei der Randomisierung "undefinierte Variable"
Das Problem dürfte gewesen sein, dass er seine Frage vom Typ Gleichung / Formel / Equation "random" genannt hat, dann später aber per "randnumber" drauf zu greifen wollte. Da beschwert sich Limesurvey natürlich zu recht.
I answer at the LimeSurvey forum in my spare time, I'm not a LimeSurvey GmbH employee.
No support via private message.
The topic has been locked.
- Joffm
-
- Offline
- LimeSurvey Community Team
-
Less
More
- Posts: 12906
- Thank you received: 3969
4 years 8 months ago #187730
by Joffm
Volunteers are not paid.
Not because they are worthless, but because they are priceless
Replied by Joffm on topic Probleme bei der Randomisierung "undefinierte Variable"
Eben.
Da war keine Lösung zu beschreiben.
Dies sprang einem ja in der angezeigten Logik-Datei direkt ins Auge, was ja dem Fragesteller auch aufgefallen war.
Joffm
Da war keine Lösung zu beschreiben.
Dies sprang einem ja in der angezeigten Logik-Datei direkt ins Auge, was ja dem Fragesteller auch aufgefallen war.
Joffm
Volunteers are not paid.
Not because they are worthless, but because they are priceless
The topic has been locked.
- Asillnis_200501
-
- Offline
- Banned
-
Less
More
- Posts: 5
- Thank you received: 0
4 years 8 months ago - 4 years 8 months ago #187732
by Asillnis_200501
Replied by Asillnis_200501 on topic Probleme bei der Randomisierung "undefinierte Variable"
Danke an Euch beide!! ")
Last edit: 4 years 8 months ago by Asillnis_200501.
The topic has been locked.
- Asillnis_200501
-
- Offline
- Banned
-
Less
More
- Posts: 5
- Thank you received: 0
4 years 8 months ago - 4 years 8 months ago #187733
by Asillnis_200501
Replied by Asillnis_200501 on topic Probleme bei der Randomisierung "undefinierte Variable"
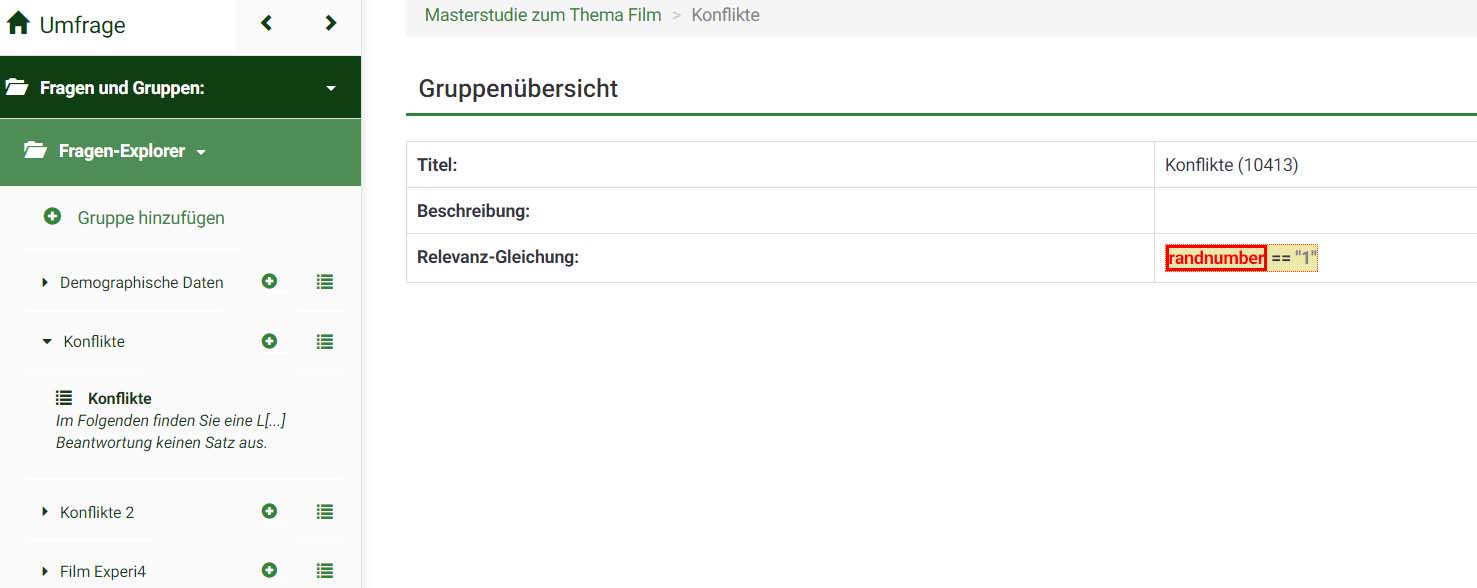
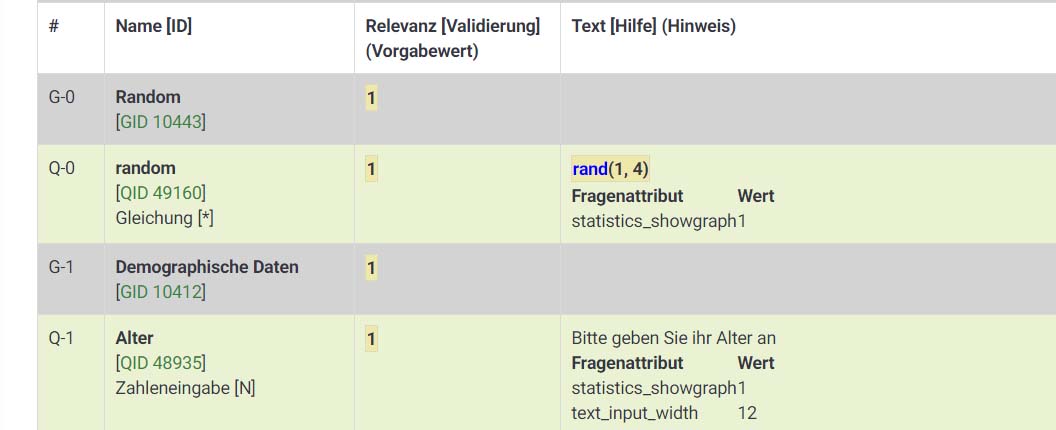
Ich habe dasselbe Problem, dass bei mir - obwohl ich die Variable einheitlich definiert habe und darauf referenziere - 'random' als undefinierte Variable angezeigt wird. Ich habe die .lss-Datei angehängt.
Mein Ziel ist, eine Studie durchzuführen, bei dem Probanden am Anfang randomisiert einem von vier Szenarien zugeordnet werden - also ein 2x2-between-subject-design. In jedem Szenario sollen ungefähr 30 Probanden teilnehmen, sodass am Ende in allen Szenarien insgesamt 120 Probanden teilgenommen haben. Dabei wird der Einsatz von Smileys bei verschiedenen Servicekanälen untersucht:
Szenario1: E-Mail mit Text+Smiley
Szenario2: Live-Chat mit Text+Smiley
Szenario3: E-Mail mit nur Text (ohne Smiley)
Szenario4: Live-Chat mit nur Text (ohne Smiley)
(Die Szenarien sind dabei immer ein Bild/Screenshot von bspw. einer E-Mail-Nachricht mit Text und Smiley)
Szenario 3 und 4 dienen also zur Kontrolle. Bei der Auswertung möchte ich dann eine zweifaktorielle ANOVA und gegebenenfalls eine Kontrastanalyse durchführen. Ist mein Vorgehen im Hinblick auf die Auswertung sinnvoll? Also, dass die Daten dann sinnvoll und leicht (zu SPSS) exportiert werden können. Ich frage, da ich vorher noch nie mit LimeSurvey gearbeitet habe und es ärgerlich wäre, die Studie durchgeführt zu haben und dann durch den Studienaufbau Fehler oder unüberschaubare Daten zu bekommen.
Als Alternative zur Randomisierung habe ich mir noch überlegt vier gleiche Umfragen zu erstellen, die sich nur in den Szenarien unterscheiden und die Ergebnisse dann "zusammenzuführen". Aber praktischer wäre natürlich eine Umfrage, wenn das möglich und nicht mit zu viel Aufwand verbunden ist.
Ganz liebe Grüße,
Stefan
Mein Ziel ist, eine Studie durchzuführen, bei dem Probanden am Anfang randomisiert einem von vier Szenarien zugeordnet werden - also ein 2x2-between-subject-design. In jedem Szenario sollen ungefähr 30 Probanden teilnehmen, sodass am Ende in allen Szenarien insgesamt 120 Probanden teilgenommen haben. Dabei wird der Einsatz von Smileys bei verschiedenen Servicekanälen untersucht:
Szenario1: E-Mail mit Text+Smiley
Szenario2: Live-Chat mit Text+Smiley
Szenario3: E-Mail mit nur Text (ohne Smiley)
Szenario4: Live-Chat mit nur Text (ohne Smiley)
(Die Szenarien sind dabei immer ein Bild/Screenshot von bspw. einer E-Mail-Nachricht mit Text und Smiley)
Szenario 3 und 4 dienen also zur Kontrolle. Bei der Auswertung möchte ich dann eine zweifaktorielle ANOVA und gegebenenfalls eine Kontrastanalyse durchführen. Ist mein Vorgehen im Hinblick auf die Auswertung sinnvoll? Also, dass die Daten dann sinnvoll und leicht (zu SPSS) exportiert werden können. Ich frage, da ich vorher noch nie mit LimeSurvey gearbeitet habe und es ärgerlich wäre, die Studie durchgeführt zu haben und dann durch den Studienaufbau Fehler oder unüberschaubare Daten zu bekommen.
Als Alternative zur Randomisierung habe ich mir noch überlegt vier gleiche Umfragen zu erstellen, die sich nur in den Szenarien unterscheiden und die Ergebnisse dann "zusammenzuführen". Aber praktischer wäre natürlich eine Umfrage, wenn das möglich und nicht mit zu viel Aufwand verbunden ist.
Ganz liebe Grüße,
Stefan
Attachments:
Last edit: 4 years 8 months ago by Asillnis_200501.
The topic has been locked.
- Joffm
-
- Offline
- LimeSurvey Community Team
-
Less
More
- Posts: 12906
- Thank you received: 3969
4 years 8 months ago - 4 years 8 months ago #187735
by Joffm
Volunteers are not paid.
Not because they are worthless, but because they are priceless
Replied by Joffm on topic Probleme bei der Randomisierung "undefinierte Variable"
Okay, stefprano,
natürlich funktioniert es nicht.
Es ist eben nicht einheitlich.
Der Code der Frage, in welcher die Zufallszahl erzeugt wird, ist schließlich "szenariofrage".
Wie Du weißt, sind dies auch die Spaltenüberschriften in der Antworttabelle.
In "szenariofrage" wird also das Ergebnis Deiner Zufallszahl stehen.
Aber welche Gleichung hast Du eingetragen?
if(random>0, random, rand(1,4))
Dies bedeutet (mit diesem Beispiel):
"Wenn die Frage "random" einen Wert größer "0" hat, lass sie wie sie ist, ansonsten weise ihr eine Zufallszahl zwischen 0 und 4 zu."
Nur: Es gibt überhaupt keine Frage mit diesem Code ("random").
Also muss Deine Gleichung lauten:
if(szenariofrage>0, szenariofrage, rand(1,4))
Und in den Relevanzgleichungen steht dann natürlich auch "szenariofrage==1",...
Es ist ungefähr so, wie wenn ich meinen Hund "Fiffi" nenne. Wenn man ihn dann "Bello" ruft, kommt er einfach nicht.")
Übrigens ist es besser, diese Relevanzgleichung in die Gruppe zu schreiben abstatt in jede einzelne Frage der Gruppe. Dann kann es Dir nämlich passieren, dass die Gruppe angezeigt wird, diese aber keine einzige Frage enthält, aber trotzdem den "Weiter"-Button.
Übrigens hat diese Konstruktion der Zufallszahl folgenden Sinn - wobei ich
{if(is_empty(random), random, rand(1,4))} für besser halte, falls auch einmal eine Zahl von 0 - n gewünscht ist.
Da die Funktion "rand" bei jedem Aufruf der Seite neu ausgeführt wird (wie ja auch bei EXCEL), vermeidet man hiermit, dass sich die einmal zugewiesene Zufallszahl ändert.
Dies könnte z.B. vorkommen, wenn der Respondent im Fragebogen zurückgeht, oder bei gruppenweiser Darstellung.
Wurde hier auch schon des öfteren erklärt.
Und bitte, bei Einfachnennungsfragen, belasse es nicht bei den default-Antwortcodes "A1", "A2", ... sondern benutze numerische Codes.
SPSS wird es Dir danken. Denn was wäre wohl der Mittelwert von "A1", "A4", "A3" und "A2"? Bestimmt nicht "A2,5"
Hier: manual.limesurvey.org/Expression_Manager...mplemented_functions
Und hier:
manual.limesurvey.org/Expression_Manager...7BMrs.7D_Smith....22
Viel Erfolg
Joffm
P.S.
Bis jetzt haben wir ja nicht viel Deiner Studie gesehen. Dass Du die Leute Daten hochladen lässt erscheint mir bei Deiner Erklärung merkwürdig.
Ansonsten - zur Auswertefreundlichkeit verweise ich auf meinen Kommentar zu Evas Frage.
Wenn Du es wie jetzt mit mehreren Gruppen machst, musst Du die Daten später zusammenführen, damit Du Deine Tests durchführen kannst.
Daher ist es für die Auswertefreundlichkeit (vielmehr für die Arbeitserleichterung bei der Strukturierung der Daten) sicherlich immer besser, auf "Micro-Tayloring" zu setzen (falls es die Fragen zulassen)
Und jetzt noch ein letzter Satz:
Da sich ja laut Berufsgruppen-Frage die Studie an Gesamtbevölkerung richtet, finde ich es ein wenig unverschämt, die Leute einfach zu duzen. Insbesondere noch, da als Basis-Sprache "deutsch" gewählt ist, und nicht "deutsch (informal)"; d.h. die System-Texte kommen in der "Sie"-Form.
natürlich funktioniert es nicht.
Das ist doch derselbe Fehler, den der ursprüngliche Threadersteller gemacht hat, und den holch noch einmal erklärt hat.Ich habe dasselbe Problem, dass bei mir - obwohl ich die Variable einheitlich definiert habe und darauf referenziere - 'random' als undefinierte Variable angezeigt wird
Es ist eben nicht einheitlich.
Der Code der Frage, in welcher die Zufallszahl erzeugt wird, ist schließlich "szenariofrage".
Wie Du weißt, sind dies auch die Spaltenüberschriften in der Antworttabelle.
In "szenariofrage" wird also das Ergebnis Deiner Zufallszahl stehen.
Aber welche Gleichung hast Du eingetragen?
if(random>0, random, rand(1,4))
Dies bedeutet (mit diesem Beispiel):
"Wenn die Frage "random" einen Wert größer "0" hat, lass sie wie sie ist, ansonsten weise ihr eine Zufallszahl zwischen 0 und 4 zu."
Nur: Es gibt überhaupt keine Frage mit diesem Code ("random").
Also muss Deine Gleichung lauten:
if(szenariofrage>0, szenariofrage, rand(1,4))
Und in den Relevanzgleichungen steht dann natürlich auch "szenariofrage==1",...
Es ist ungefähr so, wie wenn ich meinen Hund "Fiffi" nenne. Wenn man ihn dann "Bello" ruft, kommt er einfach nicht.
Übrigens ist es besser, diese Relevanzgleichung in die Gruppe zu schreiben abstatt in jede einzelne Frage der Gruppe. Dann kann es Dir nämlich passieren, dass die Gruppe angezeigt wird, diese aber keine einzige Frage enthält, aber trotzdem den "Weiter"-Button.
Übrigens hat diese Konstruktion der Zufallszahl folgenden Sinn - wobei ich
{if(is_empty(random), random, rand(1,4))} für besser halte, falls auch einmal eine Zahl von 0 - n gewünscht ist.
Da die Funktion "rand" bei jedem Aufruf der Seite neu ausgeführt wird (wie ja auch bei EXCEL), vermeidet man hiermit, dass sich die einmal zugewiesene Zufallszahl ändert.
Dies könnte z.B. vorkommen, wenn der Respondent im Fragebogen zurückgeht, oder bei gruppenweiser Darstellung.
Wurde hier auch schon des öfteren erklärt.
Das sind ja die Basics. Im Normalfall machst Du Dir doch einen Prototypen der Studie - wie er ja jetzt schon existiert - also pro Gruppe zwei Fragen, eine Einfachnennung und eine Mehrfachnennung, gibst ein paar Daten ein, und guckst, wie es aussieht.Also, dass die Daten dann sinnvoll und leicht (zu SPSS) exportiert werden können. Ich frage, da ich vorher noch nie mit LimeSurvey gearbeitet habe und es ärgerlich wäre, die Studie durchgeführt zu haben und dann durch den Studienaufbau Fehler oder unüberschaubare Daten zu bekommen.
Und bitte, bei Einfachnennungsfragen, belasse es nicht bei den default-Antwortcodes "A1", "A2", ... sondern benutze numerische Codes.
SPSS wird es Dir danken. Denn was wäre wohl der Mittelwert von "A1", "A4", "A3" und "A2"? Bestimmt nicht "A2,5"
Dies ist kein Workaround. Das ist einfach die Anwendung der "if"-Funktion.Und die Manipulation der Randomisierung ist ein cleverer Workaround! Danke auch dafür!
Hier: manual.limesurvey.org/Expression_Manager...mplemented_functions
Und hier:
manual.limesurvey.org/Expression_Manager...7BMrs.7D_Smith....22
Viel Erfolg
Joffm
P.S.
Bis jetzt haben wir ja nicht viel Deiner Studie gesehen. Dass Du die Leute Daten hochladen lässt erscheint mir bei Deiner Erklärung merkwürdig.
Ansonsten - zur Auswertefreundlichkeit verweise ich auf meinen Kommentar zu Evas Frage.
Wenn Du es wie jetzt mit mehreren Gruppen machst, musst Du die Daten später zusammenführen, damit Du Deine Tests durchführen kannst.
Daher ist es für die Auswertefreundlichkeit (vielmehr für die Arbeitserleichterung bei der Strukturierung der Daten) sicherlich immer besser, auf "Micro-Tayloring" zu setzen (falls es die Fragen zulassen)
Und jetzt noch ein letzter Satz:
Da sich ja laut Berufsgruppen-Frage die Studie an Gesamtbevölkerung richtet, finde ich es ein wenig unverschämt, die Leute einfach zu duzen. Insbesondere noch, da als Basis-Sprache "deutsch" gewählt ist, und nicht "deutsch (informal)"; d.h. die System-Texte kommen in der "Sie"-Form.
Volunteers are not paid.
Not because they are worthless, but because they are priceless
Last edit: 4 years 8 months ago by Joffm.
The following user(s) said Thank You: holch
The topic has been locked.
Moderators: Joffm